
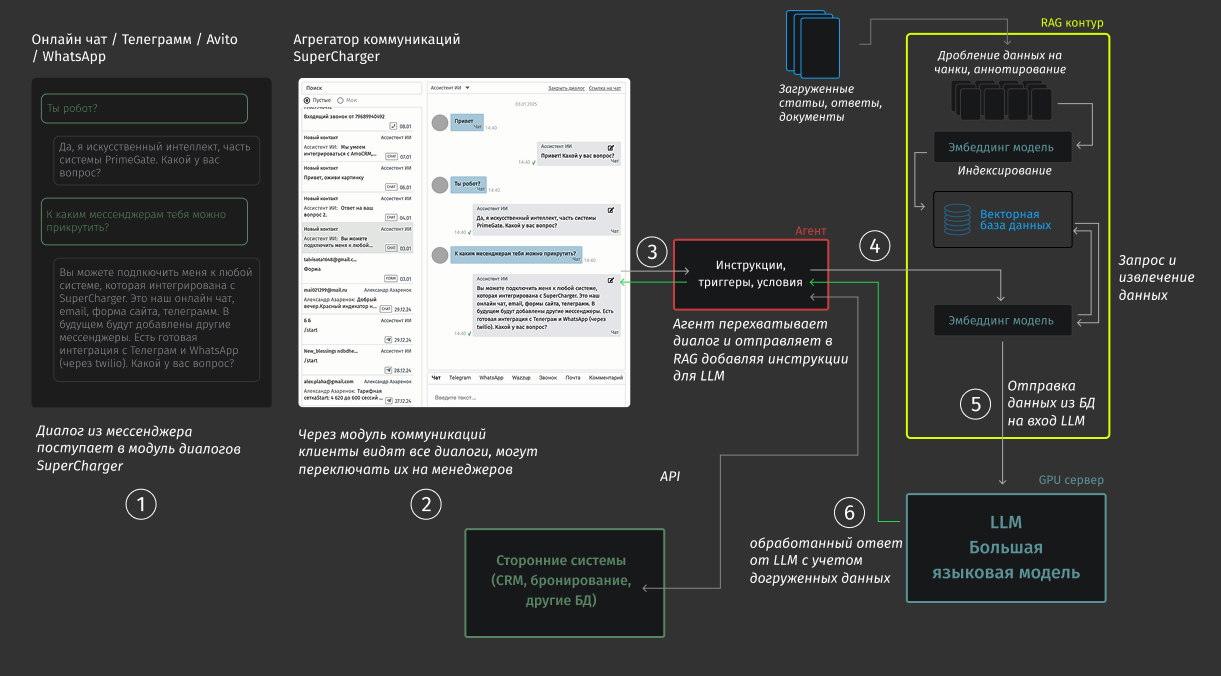
Как они взаимодействуют с нейросетью и CRM-системами?
Многие компании грезят возможностью передать некоторые бизнес-задачи на ИИ. Кто-то планирует перевести консультации на ИИ, кто-то хочет, чтобы ИИ продавал, вел по воронке. Так или иначе, для общения с нейросетью нужны специализированные сервисы, позволяющие реализовать общение в контексте вашего бизнеса: понимая специфику оказания услуг, учитывая цены, взаимодействуя с системами управления.
RAG - это нейросеть?
RAG (Retrieval-Augmented Generation) — это генерация ответа, дополненная результатами поиска. Нейросеть генерирует ответ, основываясь на дополненных данных из базы знаний. Поскольку обучить нейросеть (ее ядро) именно вашему бизнесу дорого, долго и бессмысленно - на вход нейросети подаются доп. данные, позволяющие нейросети понимать аспект. Сами по себе нейросетевые модели уже очень хорошо могут разбираться в контексте. Могут понимать суть вопроса и отвечать, но не знают специфических моментов. RAG позволяет дообогатить нейросеть дополнительными данными, которые будут поступать в нейросеть, и она будет ими оперировать.
Другими словами, RAG - это инфраструктура, позволяющая подготовить определенным образом базу знаний (ваши документы), чтобы нейросеть могла обращаться к этим данным и выдавать ответы согласно этим знаниям.
Как RAG работает?
Внутри RAG есть так называемый эмбеддер. Это тоже нейросетевая модель, но меньшего размера, нежели основная модель во всей системе. Эмбеддер преобразовывает загруженные данные в векторный формат и помещает их в векторную базу данных. Помимо этого, для улучшения поиска данные проходят преобразования: дробятся на куски (чанки) и при необходимости аннотируются (добавляются пояснения).
Также, эмбеддер переводит обращение пользователя из диалога в векторный формат, чтобы найти соответствие запрошенным данным в векторной базе. Далее, данные из векторной БД отправляются уже в большую языковую модель вместе с инструкциями из промта, контекстом диалога (несколько последних сообщений клиента) из агента и самим сообщением клиента. Большая языковая модель принимает эти данные на вход, а на выходе предоставляет ответ. Кроме того, после большой языковой модели может быть применена еще одна модель чуть меньшего размера, которая оценивает ответ. В нашей система это называется “валидатор”.
Проблемы с подготовкой данных для RAG
Безусловно, бизнес хочет как можно более простой процесс загрузки данных в RAG и поддержки их актуальности. Нужно учитывать, что на данном этапе развития RAG-систем, к сожалению, не все данные можно использовать. Например, технически можно загрузить телефонные разговоры, далее перевести их в текст, но появляется множество проблем.
Нужно дробить разговор по смыслам и размечать диалог. Удалять ненужные данные. Необходимо проводить диаризацию (кто есть кто в диалоге). То есть, нужно проводить суммаризацию - переводить диалог в некоторую статью с точными смыслами. Но, если суммаризацию можно было бы провести какой-либо языковой моделью, то кто будет оценивать качество загружаемой информации? Чтобы ответ менеджера из загруженной записи был корректным и полным. Это все непросто и упирается в человеческий фактор.
На данный момент, мы работаем над качественной загрузкой сложно структурированных PDF-файлов. Как правило, в PDF-формате находятся все ключевые знания компаний: каталоги, описания продукции и прочее. Также, мы работаем над подключением сторонних источников с товарной номенклатурой.
При этом, данные возможно загружать в TXT-документе или через веб-форму с самого начала работы нашей RAG+LLM.
Как взаимодействовать со сторонними системами?
Любой бизнес хочет, чтобы нейросеть могла не только консультировать, но и закрывать сопутствующие задачи. С одной стороны, речь идет об агрегации различных коммуникаций, чтобы все входящие обращения обрабатывались ИИ-агентом. Для этого необходимо, чтобы вокруг RAG-системы были интеграционные модули, позволяющие передавать данные из разных мессенджеров.
В PrimeGate эта задача закрывается модулем SuperCharger, который агрегирует сообщения из разных мессенджеров, плюс является единым окном, в котором можно видеть все поступающие диалоги и переключать их на менеджеров.
С другой стороны, бизнес хочет, чтобы ИИ выполнял определенные административные задачи, такие как запись клиента в CRM.
В отношении логики работы с CRM нам казалось, что все достаточно просто, но на практике бизнес видит взаимодействие агентов с CRM/ERP по-разному. Кто-то хочет, чтобы ассистент уточнял в CRM возможные слоты для бронирования времени посещения, кто-то видит бизнес-процесс иначе. У каждого клиента свои походы в автоматизации.
Поэтому все интеграции со сторонними модулями мы решили перенести в наш дочерний продукт Матильда. Это no code редактор, позволяющий настроить свой сценарий автоматизации, где обращение к нашей LLM и RAG-системе будет осуществляться согласно вашему видению автоматизации.
А может нейросеть сама обращаться к сторонним базам данных?
Это чрезвычайно интересная задача, над которой мы работаем. Сложность задачи в том, что нейросеть должна обращаться напрямую к базе данных (БД).
При этом, нейросеть должна хорошо знать структуру таблиц конкретной БД и понимать, как правильно формировать запрос к базе, поскольку у каждой БД есть свои специфические условия. Плюс, такой запрос должен идти на языке базы данных, например, MySQL.
То есть, сначала RAG-система должна корректно определить запрос клиента, уточнить его, затем корректно сформировать запрос с учетом структуры, на языке базы данных, обратиться к БД, получить от нее ответ, затем интерпретировать этот ответ и далее отдать его клиенту. Для такой задачи требуется достаточно много проверок и несколько разных моделей. Но мы полагаем, что данный подход также будет реализован в рамках Матильды.




